
Het Leiden Algoritme – De efficiëntere manier van knowledge graphs creëren?
In de snel evoluerende digitale wereld staat kunstmatige intelligentie (AI) steeds meer in het middelpunt van zakelijke strategieën. Bedrijven zoeken naar innovatieve manieren om data niet alleen te begrijpen, maar ook om deze effectief te koppelen aan verschillende contexten en vakgebieden. Een essentieel hulpmiddel in deze zoektocht zijn knowledge graphs, die verbanden tussen concepten visueel en structureel in kaart brengen. Voor klanten die diepgaandere AI-oplossingen willen, gebruiken wij regelmatig RAG-methodologieën, waaronder het Leiden-algoritme. Dit artikel biedt een diepgaande blik op dit krachtige algoritme en onderzoekt hoe het de creatie van knowledge graphs kan verbeteren.
Wat zijn Knowledge Graphs?
Knowledge graphs zijn netwerken die de relaties tussen verschillende concepten of objecten weergeven. Ze helpen AI-systemen namelijk om contextueel begrip te ontwikkelen, wat essentieel is voor het leveren van relevante en accurate resultaten. Door objecten in een netwerk te verbinden, kan AI beter inspelen op de specifieke behoeften van gebruikers. Dit maakt knowledge graphs onmisbaar voor bedrijven die hun diensten willen optimaliseren en klantgerichte oplossingen willen bieden. Meer weten over onze AI-oplossingen?
De rol van gemeenschappen in Knowledge Graphs
Bij het opbouwen van knowledge graphs is het niet voldoende om alleen losse objecten met elkaar te verbinden. Het is ook cruciaal om gemeenschappen te ontdekken—groepen van objecten die veel onderlinge verbindingen hebben. Deze gemeenschappen helpen bij het identificeren van structuren en patronen binnen een netwerk. Tot nu toe werd de Louvain-methode gebruikt voor community detection, maar vanwege enkele beperkingen is het Leiden-algoritme ontwikkeld.
De beperkingen van de Louvain-methode
De Louvain-methode heeft gedurende lange tijd de standaard gevormd voor het opsporen van gemeenschappen in netwerken. Hoewel het algoritme snel en schaalbaar is, heeft het een groot nadeel: het kan gemeenschappen identificeren die niet goed intern verbonden zijn. Dit kan leiden tot onrealistische en misleidende resultaten, vooral in complexere netwerken waar nauwkeurige inzichten van groot belang zijn. Deze tekortkoming heeft geleid tot het ontwikkelen van het Leiden-algoritme, dat op verschillende vlakken superieur is.
Het Leiden-algoritme: Een verbetering
Het Leiden-algoritme is ontworpen om deze tekortkomingen te verhelpen. Het voegt een verfijningsstap toe die ervoor zorgt dat gemeenschappen die worden geïdentificeerd ook daadwerkelijk intern samenhangend zijn. Hierdoor verlaagt het de kans op gebroken of gefragmenteerde gemeenschappen en verbetert het de algehele betrouwbaarheid en consistentie van de resultaten. Dit maakt het Leiden-algoritme bijzonder waardevol, vooral voor grotere en complexere netwerken.
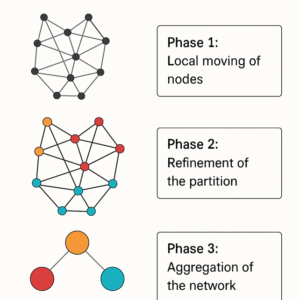
De drie fasen van het Leiden-algoritme
Het Leiden-algoritme doorloopt drie belangrijke fasen, die steeds herhaald worden tot er geen verdere verbeteringen mogelijk zijn.
- Lokale beweging van knooppunten: In deze fase worden knooppunten binnen het netwerk verplaatst naar andere gemeenschappen om de waarde van een kwaliteitsmaat, vaak modulariteit, te optimaliseren. Het algoritme richt zich enkel op de knooppunten die invloed ondergaan, waardoor het proces efficiënter is.
- Verfijnen van de partition: Dit is de belangrijkste innovatie ten opzichte van de Louvain-methode. In deze fase splitsen we de voorlopige indelingen verder op, zodat de gemeenschappen wel degelijk intern verbonden zijn. Fragmentatie wordt zo voorkomen en de resultaten worden consistenter.
- Aggregatie van het netwerk: Na het identificeren van gemeenschappen worden deze samen gevoegd tot “superknopen”. Dit resulteert in een nieuw, kleiner netwerkniveau waarop het proces kan worden herhaald. Door deze iteratieve aanpak werkt het Leiden-algoritme continu aan het verfijnen van de structuur en het bereiken van een kwalitatief goede indeling.
Kwaliteitsmaat en resolutie
Het Leiden-algoritme gebruikt een kwaliteitsfunctie zoals modulariteit en stelt een resolutieparameter in. Deze parameter stelt onderzoekers in staat om de omvang van de gevonden gemeenschappen te bepalen. Bij lage resolutie zullen grotere clusters worden gevonden, terwijl een hoge resolutie leidt tot fijnmazige gemeenschappen. Dit maakt het algoritme uiterst flexibel in verschillende disciplines en onderzoekstoepassingen.
Voordelen ten opzichte van Louvain
Het Leiden-algoritme heeft diverse duidelijke voordelen ten opzichte van de Louvain-methode:
- Interne verbondenheid: Elke gemeenschap die wordt gevonden is een echt samenhangend geheel, wat de kwaliteit van de resultaten verhoogt.
- Betere resultaten: Leiden hindert vaak clusters te vinden die beter aansluiten bij de echte netwerktopologie, wat leidt tot betrouwbaardere inzichten.
- Efficiëntie: Dankzij slimmere verplaatsingsstrategieën is het algoritme minstens zo snel, en vaak sneller, dan de traditionele Louvain-methode.
- Robuustheid: Door het herhaaldelijk verfijnen en aggregeren voorkomt het algoritme dat het blijft steken in slechte of instabiele oplossingen.
Toepassingen van het Leiden-algoritme
De veelzijdigheid van het Leiden-algoritme maakt het breed inzetbaar in verschillende disciplines. In de sociale wetenschappen helpt het bij het identificeren van gemeenschappen in sociale netwerken of samenwerkingsverbanden. In de biologie en geneeskunde vindt het toepassing bij het analyseren van functionele clusters van genen of eiwitten. Ook in bibliometrie en informatica speelt het een rol bij het in kaart brengen van vakgebieden of onderzoeksclusters op basis van citatiepatronen. Door de betrouwbaarheid en efficiëntie heeft het Leiden-algoritme zich snel bewezen als een waardevol instrument in zowel de wetenschap als de praktische toepassingen.
Conclusie
Het Leiden-algoritme vormt een krachtig en efficiënt middel voor het creëren van knowledge graphs, waarmee organisaties een beter inzicht krijgen in dataverbondenheid en structuur. Door betrouwbare gemeenschappen te identificeren en verborgen patronen te onthullen, kunnen bedrijven en onderzoekers complexe netwerken beter begrijpen en benutten.
Bij Custers streven we ernaar om onze klanten te ondersteunen met geavanceerde AI-oplossingen en datagedreven strategieën. Bent u geïnteresseerd in het verbeteren van uw digitale aanwezigheid of het implementeren van innovatieve AI-technologieën? Neem vandaag nog contact met ons op en ontdek hoe wij u kunnen helpen uw zakelijke doelen te realiseren. Voor meer informatie kunt u ook kijken naar onze pagina over AI-automatisering.