
Wat is RAG (Retrieval Augmented Generation)?
Hallo allemaal, vandaag gaan we het hebben over een term die steeds belangrijker wordt in de wereld van AI en slimme digitale oplossingen: RAG, oftewel Retrieval Augmented Generation. Zeker als je bezig bent met het maken van AI agents, kom je dit begrip tegen. Maar wat betekent het nu precies, en waarom heb je het nodig? In deze blog neem ik je stap voor stap mee in het proces, dus laten we direct van start gaan.
Waarom heb je meer data nodig dan alleen de basisdata van een AI model?
AI agents maken is tegenwoordig een belangrijk onderwerp. In veel gevallen heb je aan alleen de basisdata van een AI model, zoals bijvoorbeeld GPT-4.8, simpelweg niet genoeg. Zo’n model is getraind op gigantische hoeveelheden tekst, maar toch kan het niet álles weten of alle mogelijke vragen beantwoorden. Stel je maar voor: een AI die diepgaande juridische adviezen moet geven, of die interne bedrijfsdocumenten moet begrijpen. Daarvoor heb je gewoonweg extra, specifieke data nodig.
En daar komt RAG om de hoek kijken. RAG staat voor Retrieval Augmented Generation. Kort gezegd: het is een manier om een AI agent toegang te geven tot extra kennis buiten zijn basis training data. Hoe werkt dat? Dat leg ik hieronder uit.
Wat is RAG eigenlijk?
RAG klinkt als een ingewikkelde technische term, maar eigenlijk is het heel eenvoudig. Het is een systeem waarbij een AI agent kennis kan ophalen uit externe informatiebronnen om betere antwoorden te geven aan de gebruiker. Die kennis ophalen kan op verschillende manieren, waarvan de meest gebruikte methoden zijn: zoeken in een database en zoeken via semantisch vergelijkbare informatie.
Het belangrijkste hierbij is dat je de AI agent niet zomaar data ‘toevoegt’ – je verbindt de agent met een externe databron. Wanneer de AI aanvoelt dat hij niet genoeg weet om een vraag te beantwoorden met zijn eigen training, dan kan hij aanvullende informatie ophalen uit deze bron. Die informatie wordt vervolgens gebruikt in de zogeheten ‘context window’: de directe focus van het AI model waarmee het antwoord wordt gegenereerd.
Hoe werkt het zoeken met RAG?
Stel je voor, je hebt een database vol juridische documenten. Als de AI een vraag krijgt over bijvoorbeeld “artikel 3 burgerlijk wetboek 1”, dan moet hij zoeken in deze database. Een simpele zoekmanier is met een zogeheten keyword search: de AI zoekt letterlijk naar documenten of pagina’s waar dat exacte woord of die exacte combinatie voorkomt. Alles wat matcht, wordt opgehaald en aan de AI getoond om tot een antwoord te komen.
Maar keyword search heeft zijn beperkingen. Denk maar aan een situatie waarbij het document ‘bw’ schrijft in plaats van ‘burgerlijk wetboek’. Hoewel het hetzelfde betekent, zou het door een strikte keyword search niet opgemerkt worden, en mis je relevante informatie.
Vector search: zoeken op betekenis in plaats van op woord
Om dit probleem op te lossen, is er een andere manier van zoeken ontwikkeld: het zogenaamde vector search. Hierbij wordt niet alleen gekeken naar de losse woorden, maar vooral naar de betekenis achter de tekst.
Hoe werkt dat? Alle documenten in je database worden eerst omgezet naar vectoren: dit zijn coördinaten in een zeer complexe, multidimensionale ruimte. Je kunt het vergelijken met een soort plattegrond, maar dan in heel veel dimensies. Woorden en concepten die inhoudelijk op elkaar lijken, liggen dicht bij elkaar op deze ‘plattegrond’. Denk bijvoorbeeld aan de termen ‘kat’ en ‘hond’ die vlak bij elkaar liggen, terwijl ‘vrachtwagen’ aan de andere kant van het universum staat.
Stel de AI krijgt een vraag. Die vraag wordt óók omgezet naar een vector. Vervolgens kijkt het systeem welke documenten in de database het dichtst bij de vraag liggen qua betekenis. Op die manier kan de AI agent relevante informatie ophalen, zelfs als er andere woorden worden gebruikt dan letterlijk in de vraag.
Dit semantisch zoeken – zoeken op basis van betekenis – zorgt ervoor dat de AI flexibel en slim kan omgaan met de data. Dit noemen we vector search.
Hybrid RAG: het beste van beide werelden
Natuurlijk zijn er situaties waarin exact zoeken op woorden nuttig blijft, zeker als je op zoek bent naar specifieke wetsartikelen of productcodes. Daarom wordt in de praktijk vaak hybrid RAG gebruikt: hierbij combineren we keyword search en vector search.
Met deze hybride aanpak kan de AI zowel exact als inhoudelijk raak zoeken. Eerst zoomt de AI mogelijk in op relevante stukken tekst met vector search, waarna deze subset nóg specifieker wordt gefilterd op keywords. Of andersom: eerst grof filteren op keyword, en daarna verfijnen op inhoud. Het mooie hiervan is dat je zo het grootste deel van alle relevante informatie uit je database kunt halen.
Context window: de grenzen van een AI’s geheugen
Een AI agent kan niet onbeperkt informatie meenemen in zijn ‘gedachten’. Wat hij op een bepaald moment kan overzien, noemen we het context window. Stel dat het een heel lang document betreft en je gooit dat in één keer in de context window, dan zal de AI soms de eerste delen alweer vergeten tegen de tijd dat hij bij het einde is.
Als je heel veel belangrijke info wilt laten meenemen, moet je slim filteren welke stukken echt noodzakelijk zijn. Doe je dat niet, dan kunnen er fouten sluipen in het antwoord of kan de AI zelfs ‘hallucineren’ – dus iets bedenken wat eigenlijk niet klopt. Daarom is het voor een betrouwbare AI agent superbelangrijk om goede RAG-processen te gebruiken.
RAG engineering: een vak apart
Het ontwikkelen en finetunen van deze systemen – dus hoe je keyword- en vector search inzet, hoe je verschillende data combineert, en op welke manier de AI agent de best mogelijke set van informatie voorgeschoteld krijgt – noemen we RAG engineering. Dit is een specialisme op zich en ontzettend belangrijk bij het bouwen van moderne, krachtige AI agents.
Kortom, als je bezig bent met het ontwikkelen van AI-oplossingen of je wilt AI inzetten binnen jouw organisatie, onthoud dan goed dat RAG een essentieel gereedschap is. Hiermee geef je jouw AI agents toegang tot relevante, nauwkeurige en actuele kennis, zodat ze altijd het juiste antwoord paraat hebben.
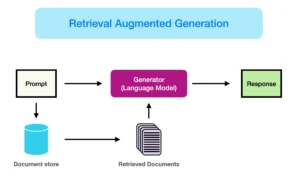
Visualisatie van het proces
Om het proces visueel te maken, kun je denken aan een eenvoudige diagram. Bovenaan staat ‘Retrieval Augmented Generation’ als centrale term. In het midden staat de generator – je AI model of language model – die een ‘prompt’ of vraag ontvangt en daar een ‘response’ of antwoord op teruggeeft. Onder deze prompt staat de documentopslag: een bron waar alle aanvullende data ligt opgeslagen. Vanuit deze document store worden relevante documenten opgehaald (Retrieved Documents), die vervolgens weer naar de generator worden gestuurd om een zo compleet mogelijk antwoord te kunnen genereren. Al deze elementen zijn onderling verbonden via pijlen die precies aangeven hoe de informatiestroom loopt.
Conclusie: waarom RAG cruciaal is voor jouw AI agent
Hopelijk is duidelijk geworden wat RAG betekent en waarom het onmisbaar is in moderne AI-toepassingen. Door slim gebruik te maken van retrieval augmented generation sla je een brug tussen statische trainingdata en actuele, relevante informatie. Of je nu juridische documenten wilt doorzoeken of je klantenservice wilt versterken: RAG zorgt voor snelle, accurate en op maat gemaakte antwoorden.
Ben je benieuwd hoe wij bij Custers kunnen helpen met het ontwikkelen van slimme AI agents en RAG-oplossingen voor jouw bedrijf? Neem vandaag nog vrijblijvend contact met ons op. Samen bouwen we aan digitale oplossingen die jouw organisatie écht verder helpen. Lees ook meer over onze AI-oplossingen.