
In de vorige blogs leerden we wat een neural network is en hoe het is opgebouwd uit lagen en neuronen. Maar hoe weet een netwerk eigenlijk of het iets goed of fout doet? En belangrijker nog: hoe leert het van zijn fouten?
In deze blog leggen we uit hoe een neuraal netwerk leert met behulp van data, cost functions en gradient descent.
Elk leerproces begint met voorbeelden. In het geval van een neural network geef je het input, zoals een afbeelding van een handgeschreven cijfer, én het juiste antwoord: “dit is een 3”.
Deze combinatie noemen we gelabelde data.
Het netwerk probeert op basis van deze input zelf te raden welk cijfer er op de afbeelding staat. Dat gebeurt met willekeurige instellingen (gewichten), dus in het begin is het antwoord meestal fout. Dat is niet erg — want juist daar begint het leren.
Voorbeeld: het netwerk zegt “80% kans dat het een 8 is”, terwijl het een 3 is.
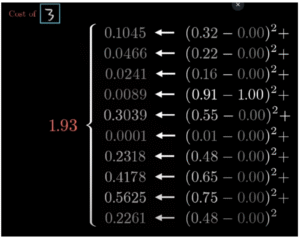
Om te leren, moet het netwerk weten hoe ver het naast de waarheid zat. Dat doen we met een cost function: een wiskundige formule die het verschil berekent tussen de output van het netwerk en de echte uitkomst.
Bijvoorbeeld:
Het netwerk zegt: 0.88 kans op ‘3’
De echte waarde is: 1.00
Verschil: 0.12 → (0.88 – 1.00)² = 0.0144
We berekenen dit voor alle mogelijke cijfers (0 t/m 9) en tellen de verschillen bij elkaar op. Zo krijg je één getal dat de fout van het hele model bij dat ene voorbeeld uitdrukt. Hoe lager dat getal, hoe beter.
Dit getal noemen we de “cost” — een maat voor hoe slecht het model presteert.
Natuurlijk leert het netwerk niet van één voorbeeld. Het krijgt duizenden plaatjes met juiste antwoorden gevoerd. Voor elk plaatje wordt een cost berekend.
Door het gemiddelde van al die kosten te nemen, weet het netwerk hoe goed het gemiddeld presteert.
Dit noemen we de totale loss of cost van het model.
Doel: de gemiddelde cost zo laag mogelijk krijgen.
(zie afbeelding van een cost curve)
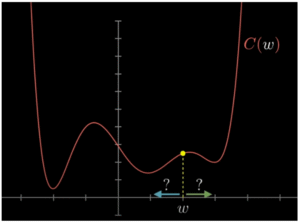
Als de cost te hoog is, wil het netwerk zich verbeteren. Maar hoe?
Het moet weten welke kant het op moet met de instellingen (weights en biases) om de cost te verlagen.
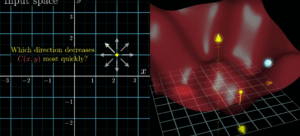
Dit gebeurt met een techniek die gradient descent heet.
Stel je voor dat je in een donker dal staat en de bodem (het perfecte model) probeert te vinden. Je voelt aan de helling onder je voeten welke kant omlaaggaat, en zet daar een stap naartoe.
Wiskundig gezien berekent het netwerk de gradiënt: dit is de richting waarin de cost het snelst daalt als je een parameter verandert. Elke weight en bias krijgt zijn eigen aanpassing.
Hoe steiler de helling (gradiënt), hoe groter de aanpassing.
Een modern neural network kan tienduizenden parameters hebben. Het bijzondere is dat het netwerk voor elk van deze duizenden weights en biases individueel bepaalt wat er moet gebeuren.
Moet weight 1 omlaag?
Moet bias 2 iets omhoog?
Moet weight 10.245 nauwelijks worden aangepast?
Het netwerk gebruikt de gradiëntvector om alle richtingen tegelijk aan te passen, telkens in kleine stapjes. Dit wordt iteratief herhaald, net zolang tot de cost minimaal is.
Vergelijk het met een beeldhouwer die steeds een klein stukje weghaalt tot het beeld perfect is.
Het leerproces stopt niet na één ronde. Het netwerk blijft data verwerken, fouten meten en bijsturen. Elke keer wordt het iets beter. Hoe vaker dit gebeurt — en hoe meer data het ziet — hoe slimmer het netwerk wordt.
Omdat alles vloeiend en geleidelijk gebeurt. Neuronen geven geen ja/nee antwoord, maar een waarde tussen 0 en 1. Daardoor kan het model precies bijstellen wat nodig is, zonder te schokken.
En omdat de cost-functie en gradiënt op wiskunde gebaseerd zijn, kan het netwerk zelf ontdekken hoe het zich moet verbeteren — zonder dat een mens dat handmatig hoeft te doen.
Een neural network leert in vijf stappen:
Het krijgt gelabelde voorbeelden (input + correct antwoord)
Het vergelijkt zijn voorspelling met de waarheid (cost)
Het berekent de gemiddelde fout over duizenden voorbeelden
Het bepaalt welke kant het op moet om de fout te verkleinen (gradient)
Het past alle instellingen beetje bij beetje aan (gradient descent)
En dit herhaalt zich — net zolang tot het netwerk zelfverzekerd en nauwkeurig voorspelt.
Laat het me weten als je dit wilt laten omzetten naar een visuele presentatie of animatie. In de volgende blog kijken we naar overfitting: wat er gebeurt als een netwerk té goed leert en zijn lesjes te letterlijk neemt.
(deze tekst is ge fine-tuned door AI)
Inspiratiebron: https://www.youtube.com/watch?v=IHZwWFHWa-w